Collect
The Collect step in Snappit is designed for extracting structured lists of data across multiple pages. It enables users to crawl paginated content—such as product listings, search results, or directories—by repeatedly collecting data from consistent DOM structures and moving through pages automatically.
📥 Purpose
To gather a list of structured items from one or more pages by identifying repeatable container elements and their subfields.
🧭 Behavior
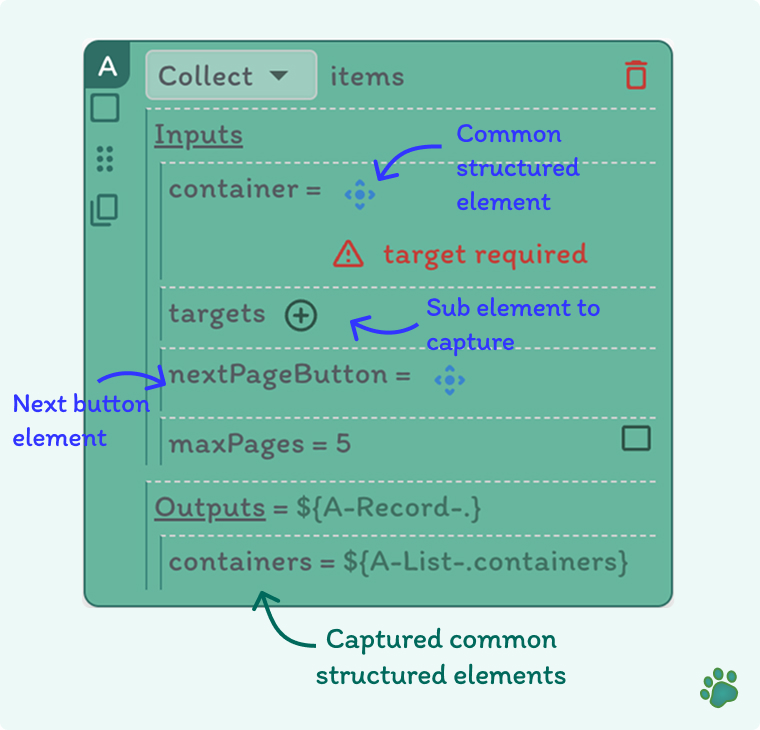
- Identifies container elements (e.g., product cards, listing items)
- Extracts data from specified sub-targets within each container (e.g., title, price, rating)
- Navigates to the next page after collecting current page’s data
- Repeats this process until max pages are reached or no more pages exist
- Outputs a list of collected items
⚙️ Configuration
| Field | Description |
|---|---|
container | A DOM element that wraps each item (e.g., product card) |
targets | List of sub-elements within the container to collect (e.g., price, name) |
nextPageButton | The clickable target that navigates to the next page |
maxPages | (Optional) Maximum number of pages to crawl (defaults to 5) |
✅ Use Cases
- Collecting product listings from e-commerce sites
- Scraping job postings from paginated directories
- Gathering reviews or comments from forums
- Crawling blog archives
The Collect step streamlines complex data-gathering tasks by turning repetitive navigation and extraction into a single powerful action that outputs a structured List of items.